스스로 검사하고 행동하다 — 판정·도구·에이전트·MCP를 한 지도에
LLM은 함수를 실행하지 않는다. 구조화된 요청만 내뱉고 실행은 바깥 코드가 한다. 밥비서에서 우리가 이름도 모른 채 깔아둔 판정 레이어부터, function calling·agent·MCP가 같은 그림의 세 층위로 묶이기까지의 기록.
지난 편에서 우리는 모델 입에 무엇을 떠먹일지를 다뤘다. 검색을 잘하고, 잘 주입하고, “근거에 없으면 모른다고 답하라”는 탈출구까지 줘도 — 모델은 여전히 미끄러진다. 생성이 미끄러지는 걸 막는 마지막 장치는 결국 하나뿐이었다. 만들어진 답을 누군가 다시 검사하는 것. 그 검사자 자리에 또 다른 모델을 앉히면, 검사는 사람의 손을 떠나 확장된다.
여기서부터 시스템의 성격이 바뀐다. 지금까지 LLM은 ‘말하는’ 기계였다. 이제부터는 검사하고, 행동하는 기계가 된다. 이 글은 그 전환을 한 장의 지도에 올린다 — 판정(Judge), 도구(Tool Use), 에이전트(Agent), 그리고 도구를 표준으로 꽂는 규격(MCP)까지. 그리고 늘 그렇듯, 우리는 이 이름들 중 몇 개를 이름도 모른 채 밥비서에서 먼저 쓰고 있었다.
판정은 짧게 — 이미 한 번 다룬 자리
검사자 자리에 모델을 앉히는 구조를 LLM-as-Judge라 부른다. 한 번의 호출이 답을 만들고(생성자), 또 한 번의 호출이 그 답을 채점한다(심판). 효과의 핵심은 단순하다 — 만드는 일과 검사하는 일은 다른 과제다. 빈 종이에 그럴듯한 답을 짓는 것보다, 이미 있는 답과 근거를 나란히 놓고 “이 줄이 저기서 뒷받침되나”를 따지는 게 더 쉽고 덜 환각한다.
judge(근거, 답, "모든 주장이 근거에서 뒷받침되는가? 점수와 위반 문장")
// → { score: 2, violations: ["간장 2큰술 — 근거에 없음"] }다만 심판도 LLM이라 똑같이 틀린다. 생성자와 같은 모델이면 같은 편향을 공유해 같은 실수를 사이좋게 통과시키고, 길거나 자신감 있는 답에 후한 점수를 주는 편향도 알려져 있다. 그래서 다수결을 보거나, 이종 모델을 쓰거나, 기준을 잘게 쪼개 하나씩 묻는다.
판정을 빌드타임 코퍼스 게이트로 깊이 운영한 이야기는 별도 글에서 이미 풀었으니, 여기서는 개념 지도의 한 노드로만 짚고 지나간다. 한 걸음 넓히면, 이 판정은 RAG 평가(evaluation) 전체로 이어진다. RAG는 두 군데서 틀리므로 평가도 둘로 갈린다 — 검색이 좋았나(정답 근거를 잘 건졌는가는 recall, 군더더기는 적은가는 precision), 답이 좋았나(답이 근거에 충실한가는 faithfulness, 질문에 들어맞는가는 answer relevance). RAGAS 같은 프레임워크가 하는 일이 바로 이 넷을 LLM-as-Judge로 자동 채점해 점수판을 뽑는 것이다. “우리 RAG, 지난주보다 좋아졌어?”를 감이 아니라 숫자로 답하게 해준다.
그리고 밥비서를 보면, 우리는 이 레이어를 두 군데에 이미 깔아두었다. 빌드타임에는 코퍼스를 쌓을 때 생성물을 또 다른 판정이 거르는 품질 게이트가 있었고, 런타임에는 후보 식단을 검토해 고르는 일 자체가 판정이다. ‘LLM-as-Judge’도 ‘RAGAS’도 입에 올리지 않은 채, 양쪽에서 판정을 운영하고 있던 셈이다.
LLM은 함수를 실행하지 않는다
이제 검사에서 행동으로 넘어간다. 여기가 이 분야에서 가장 자주, 가장 크게 오해받는 지점이라 천천히 가자. 먼저 틀린 그림부터 지운다.
LLM은 함수를 실행하지 않는다. “GPT가 날씨 API를 호출했다”, “에이전트가 DB를 조회했다”는 말은 비유일 뿐, 실제로 LLM이 코드를 돌린 게 아니다. LLM이 할 수 있는 건 단 하나 — 텍스트를 내뱉는 것뿐이다. 그럼 어떻게 도구를 쓰는가.
이렇게 한다. 미리 “쓸 수 있는 도구 목록”을 LLM에게 알려준다 — 각 도구의 이름, 설명, 받을 인자의 모양(스키마)을. LLM은 답하다가 도구가 필요하다 싶으면, 그 도구를 직접 실행하는 게 아니라 “이 함수를 이 인자로 부르고 싶다”는 구조화된 요청을 텍스트로 내뱉는다. 그게 끝이다. 실행은 바깥의 코드가 한다.
[1] 우리 코드 ──▶ LLM
"질문: 30분 고단백 저녁. 도구: search_recipe(protein, max_time)"
▼
[2] LLM ──▶ 우리 코드 (실행이 아니라 '요청'을 내뱉을 뿐)
{ tool: "search_recipe", args: { protein: "chicken", max_time: 30 } }
▼
[3] 우리 코드가 진짜로 실행 ◀── 여기서만 코드가 돈다
▼
[4] 우리 코드 ──▶ LLM (결과를 프롬프트에 다시 주입)
"tool 결과: [닭가슴살 스테이크, 닭안심 구이, ...]"
▼
[5] LLM ──▶ 우리 코드
"오늘 저녁은 닭가슴살 스테이크 어때요?" (최종 답)이 왕복이 Tool Use이고, “이 함수를 이 인자로”라는 구조화된 출력을 내는 능력이 Function Calling이다. 여기서 두 가지가 결정적이다. 첫째, 2번과 3번 사이에 벽이 있다. LLM은 욕구만 말하고 실행 권한은 전적으로 바깥 코드에 있다 — 위험한 도구를 부르려 해도 우리가 거를 수 있다는 게 보안의 핵심이다. 둘째, 4번의 결과 주입은 지난 편의 context injection과 똑같은 일이다.
그럼 RAG는 이 그림 어디에 앉을까. retrieval 자체를 하나의 도구로 보면 된다. 검색이라는 tool을 LLM이 부르고(2번), 벡터 검색이 실행되고(3번), 결과가 주입되고(4번), LLM이 답한다(5번). 고전 RAG의 루프는 더 짧다 — [코드] → [검색(무조건 실행)] → [생성]. ‘부를지 말지 판단’하는 2번이 통째로 빠져 있다. 즉 고전 RAG는 LLM에게 선택권을 주지 않고 늘 검색부터 하는 특수한 경우고, Tool Use는 그 선택권을 LLM에게 돌려준 것이다.
밥비서에도 이 그림의 출력측 절반이 있다. 코퍼스 태깅 단계에서 우리는 LLM에게 “이 레시피의 속성을 정해, 반드시 정해진 JSON 스키마로”라고 요구했다. 자유 산문이 아니라 정해진 구조의 출력을 강제하는 것 — 그게 function calling의 출력측 그대로다. 호출 요청을 받아 실행하는 풀 루프까지는 가지 않았어도, ‘구조화된 출력을 강제’하는 그 절반은 빌드 파이프라인에서 매일 썼다.
한 번이 아니라, 목표를 이룰 때까지
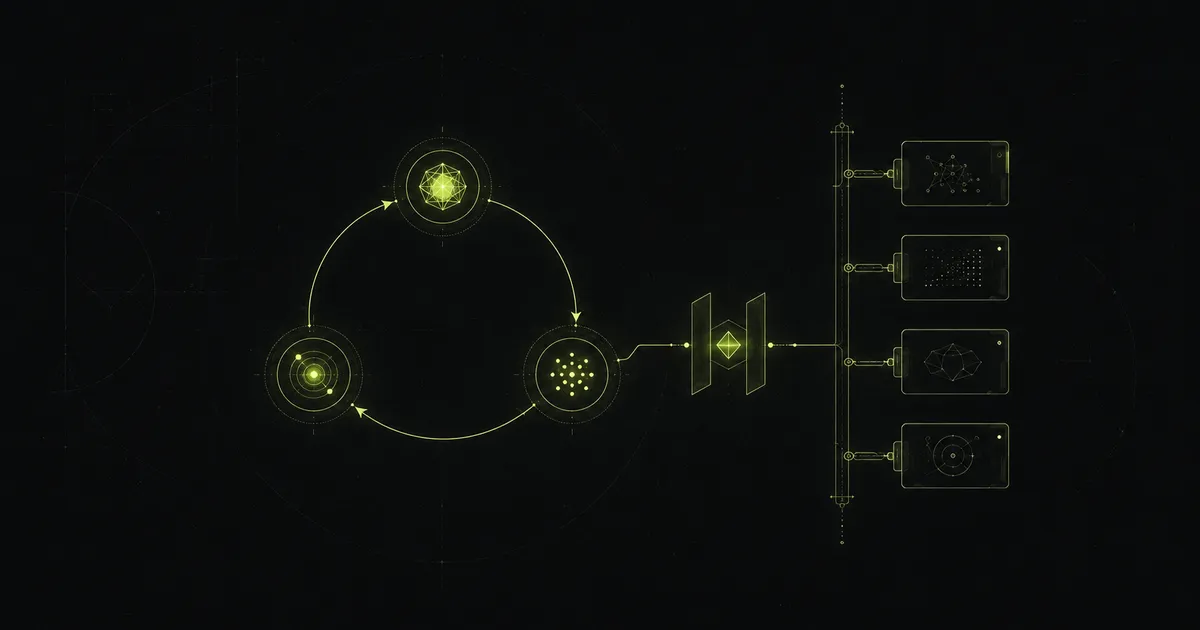
Tool Use에서 LLM은 도구를 한 번 불렀다. 한 바퀴. 그런데 현실의 문제는 한 바퀴로 안 끝난다. 첫 검색이 부실하면 다시 검색해야 하고, 한 도구의 출력이 다음 도구의 입력이 되기도 한다. 이 왕복을 목표를 이룰 때까지 LLM이 스스로 반복하게 만들면 — 그게 에이전트(Agent)다. 한 줄로 줄이면, 에이전트는 LLM(두뇌)에 도구(손)·기억·계획을 붙여 그 루프를 스스로 도는 구조다.
가장 널리 쓰이는 루프가 ReAct다. 매 바퀴 LLM은 셋을 한다 — 생각하고(지금 뭘 알고 뭘 모르나), 행동하고(어떤 도구를 부른다), 관찰한다(결과를 본다). 그 관찰을 들고 다시 생각으로 돌아가고, 충분하다 싶으면 멈춰 최종 답을 낸다.
┌──────────────────────────────────────────┐
▼ │
[Reason] "고단백 저녁이 필요. 그런데 재료를 모른다."
▼ │
[Act] 도구 호출: search_recipe(protein=chicken)
▼ │
[Observe] 결과: [닭가슴살 스테이크 ...] ──────┘ (부족하면 다시 생각으로)
▼ (충분하면 루프 종료)
[Answer] "오늘 저녁은 닭가슴살 스테이크 어때요?"이제 RAG로 돌아오면 깔끔한 연결이 생긴다. 에이전트의 눈으로 보면 검색조차 하나의 행동(Act)이다. 그러면 LLM이 매 바퀴 “지금 검색이 필요한가?”부터 판단할 수 있다. 이미 아는 질문이면 안 찾고, 결과가 부실하면 질의를 바꿔 다시 찾는다. 이게 agentic RAG다 — 검색을 강제 단계가 아니라 ‘판단해서 부르는 도구’로 풀어낸 RAG. (에이전트가 단발 태스크를 넘어 워크스트림을 소유하는 자율 운영 쪽으로 가면 이야기가 또 한 층 깊어지는데, 그건 이 지도의 범위 밖이라 다른 글의 몫으로 둔다. 여기서는 에이전트라는 개념 노드까지만.)
도구를 꽂는 표준 규격
에이전트가 도구를 여럿 쓰기 시작하면 골치 아픈 문제가 생긴다. 도구마다 연결 방식이 제각각이라는 것. A는 REST, B는 GraphQL, C는 사내 RPC… LLM에게 도구를 알려주는 형식도, 결과를 받는 형식도 다 다르면 에이전트 하나에 도구 열 개를 붙이는 데 접착 코드만 산더미가 되고, 그 짓을 에이전트마다 처음부터 다시 한다.
MCP(Model Context Protocol)가 정리하려는 게 그거다. 흔히 USB-C에 빗대지만, 비유에서 멈추면 안 된다. 단자 ‘아래’에서 실제로 무엇이 표준화되는지가 핵심이다. MCP가 못 박는 건 둘이다 — 도구를 알리는 형식(각 도구가 이름·설명·인자 스키마를 정해진 모양으로 내놓는다)과 도구를 부르는 규약(호출과 결과 반환을 도구 종류와 무관하게 같은 메시지로 주고받는다).
{ name: "search_recipe",
description: "조건으로 레시피 검색",
parameters: { protein: "string", max_time: "number" } }앞 그림을 떠올려 보면 분명해진다. LLM이 “이 함수를 이 인자로”라는 구조화된 요청을 내고 바깥 코드가 실행해 결과를 돌려줬다 — MCP는 그 ‘도구 정의’와 ‘호출·결과’ 부분을 표준 규격으로 못 박은 것이다. 그래서 MCP 서버로 한 번 감싼 도구는, MCP를 말하는 어떤 에이전트에든 다시 짤 필요 없이 꽂힌다. 도구 제작자와 에이전트 제작자가 서로를 모르고도 협업하게 만드는 공용어인 셈이다.
우리 스택에도 이미 한 가닥이 있다. 개발 환경에서 DB를 다룰 때 postgresql-mcp를 쓰도록 해 둔 설정 — Postgres를 MCP 규격으로 감싸, 에이전트가 표준 방식으로 쿼리하게 한 것이다. 거창한 자율 시스템이 아니라, 일상 개발 도구 하나를 표준 단자에 꽂아 둔 작은 사례다.
같은 그림의 세 층위
여기서 세 이름이 한 문장으로 묶인다. Function calling은 LLM이 도구 호출을 표현하는 법이고, Agent는 그 호출을 반복해서 엮는 법이며, MCP는 그 도구들을 표준으로 꽂는 법이다. 표현·반복·연결 — 같은 그림의 세 층위다. 따로 외울 개념 셋이 아니라, “LLM이 바깥 세계를 만진다”는 한 동작을 다른 배율로 본 것뿐이다.
우리에게 이 지도가 주는 교훈은 매번 같다. first principle로 문제를 먼저 풀면, 나중에 이름을 만났을 때 그 이름이 비로소 살로 붙는다. “코퍼스 태깅은 정해진 JSON으로 받아야 한다”던 실무 결정은 function calling의 출력측이었고, “생성물은 또 다른 판정이 걸러야 한다”던 게이트는 LLM-as-Judge였다. 우리는 이름표를 보기 전에 그 길을 걸었고, 이름을 붙이고 나니 어디까지 더 갈 수 있는지가 보인다.
한 가지는 분명히 해 둔다. 이 모든 판정·도구·에이전트 이야기는 데이터를 빚고 검증하는 자리의 일이다. 사용자에게 나가는 주 단위 식단을 짜는 코어 엔진은 이것과 별개로, LLM 없이 도는 결정론 알고리즘이다. 행동하는 레이어와 결정론 레이어를 섞지 않는 게 우리 설계의 전제다.
길게 일하려면, 기억이 있어야 한다
에이전트를 정의할 때 슬쩍 끼워둔 단어가 있다 — 기억. LLM은 본래 기억이 없다. 한 번의 호출이 끝나면 방금 한 대화를 깨끗이 잊는다. 에이전트가 한 바퀴를 넘어 길게 일하려면 이 망각을 메워야 한다. 다음 편(Part 5)에서 단기·장기 기억, GraphRAG, 그리고 컨텍스트를 살아 있게 유지하는 lifecycle로 들어간다. 그리고 그 기억을 꺼내 쓰는 일은 — 또 RAG다.
이름 없이 먼저 풀었던 문제에 정확한 이름을 붙이는 이 작업은, 결국 같은 메커니즘을 다른 도메인에 옮겨 심기 위한 지도다.