
데이터가 곧 자산 — 같은 게이트를 당신의 도메인에
모델은 갈아끼울 수 있지만, 한 도메인의 데이터를 정제·태깅·검증·평가·grounding으로 길들여 온 게이트는 복제하기 어렵다. "데이터가 8할" 시리즈를 닫으며 — 데이터 공정이 곧 durable moat이자 출처 규율이다.

AI는 인프라 위에서 자란다
AI의 진짜 몸은 화면 밖 전기·물·반도체 위에 있고, 그 인프라는 소수에게 쏠린다. 인프라를 못 가진 작은 회사가 설 자리는 어디인가 — 같은 모델로도 결과를 가르는 데이터·피드백 루프·평가, 그리고 그 위에서 문제를 끝까지 푸는 일에 대한 생각.

유창함은 정확함이 아니다 — 판단을 사실에 묶는다
LLM이 유창하게 답한다고 맞는 건 아니다. 그럴듯한 허구를 막으려면 판단을 검증 가능한 도메인 사실에 묶어야 한다. 한국어 식문화에서 제철·구성 같은 사실에 LLM 판단을 grounding해 온, 유창함과 정확함을 가르는 게이트의 기록.
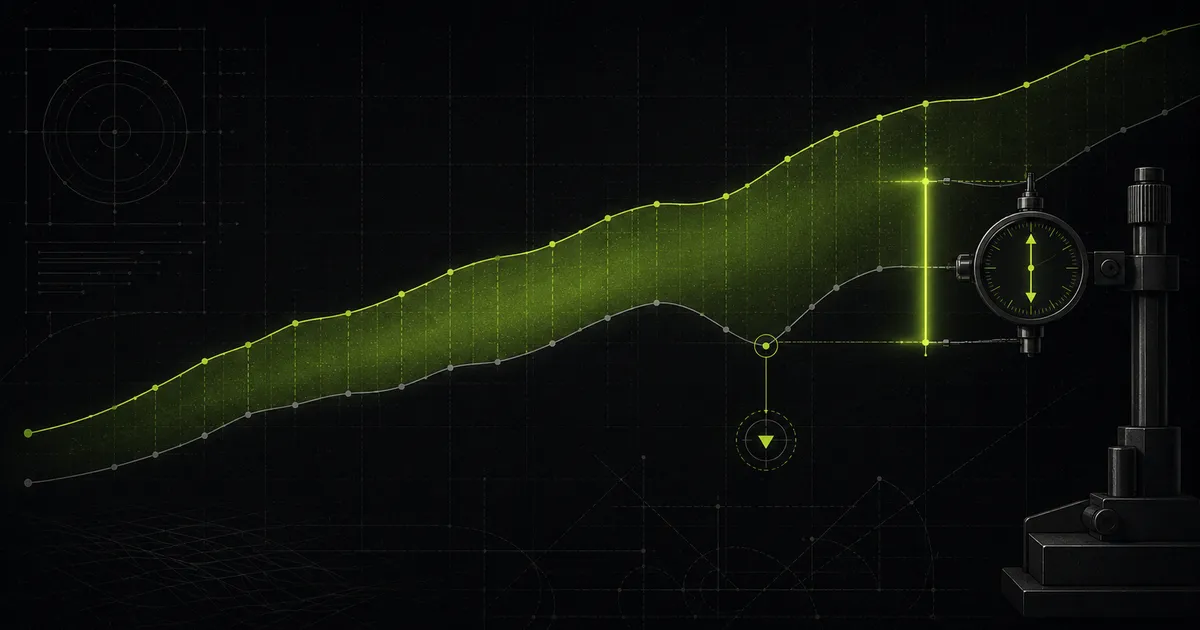
"좋아졌다"를 측정하는 법
AI 품질에서 가장 위험한 문장은 "좋아진 것 같다"이다. 규칙 하나, 판단자 하나를 바꿀 때마다 같은 잣대로 다시 재고 회귀를 먼저 잡는 일 — 한국어 도메인 코퍼스에서 "좋아졌다"를 주장이 아니라 측정으로 바꾼 eval 하네스 이야기.

그럴듯한 허구를 거르는 자리 — LLM을 판단자로
생성형 AI의 출력은 유창하지만 그게 곧 정확함은 아니다. 더 똑똑한 생성 대신, 우리는 LLM을 판단자 자리로 옮겼다. 코퍼스에 그럴듯한 허구가 쌓이지 않도록 생성과 판정을 분리하고, 판정을 데이터 승격 게이트로 세운 기록.

무엇으로 분류할지가 도메인 지식이다
데이터에 태그를 붙이는 건 누구나 한다. 무엇으로 나눌지를 정하는 일은 다르다 — 분류 축의 선택이 곧 도메인 이해의 증거다. 계절·제철·난이도·구성 같은 축을 어떻게 설계하고, 같은 레시피에 매번 같은 라벨이 붙도록 일관성을 어떻게 지키는가.
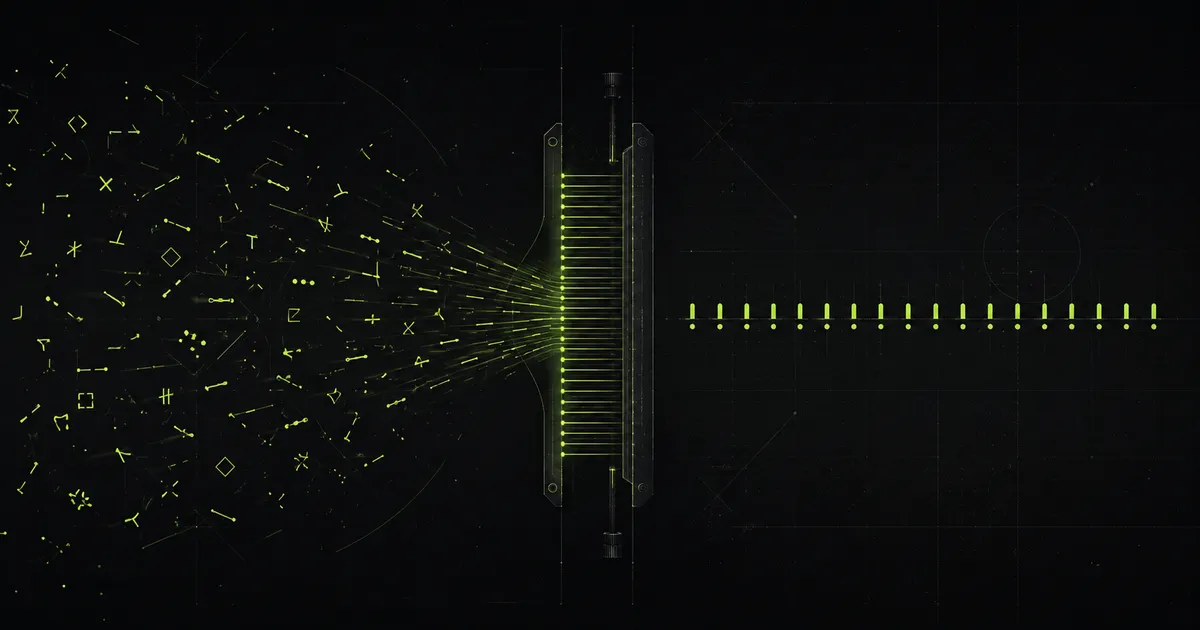
한국어는 지저분하다 — 정규화의 현실
한국어 레시피는 같은 재료·단위·조리법을 수십 가지로 적는다. 표기·단위·조리표현의 흔들림을 일관 형태로 모으는 정규화는 잡일이 아니라 "같다/다르다"의 경계를 긋는 의미 결정의 공정이다.

데이터가 8할이라면, 그 8할을 어떻게 다루나
"데이터가 8할"은 누구나 말한다. 정작 그 8할이 무엇으로 이루어졌는지는 잘 말하지 않는다. 한국어 식문화 도메인에서 우리가 매일 굴리는 정제·태깅·검증·평가·grounding이라는 데이터 공정의 해부도, 그리고 이를 한 편씩 펼칠 시리즈의 출발점.